|
(Click on logo to return to main page)
|
CarLibrary.org - Archive/Collections Basics
|
(Click on logo to return to main page)
|
|
How and Why Should a Collector/Collection/Museum Organize Their Car(s), Photos, Books and Documents? Many car hobbyists and collectors recognize the benefits of having an inventory of their car(s), photos, books and documentation. Surprisingly, very few collections have more than a simple inventory on a spreadsheet, in Excel or similar. This web page describes a step-by-step process which will help a collector or a museum professional evolve from not-much organization or a simple inventory - first to a well-designed inventory which can be the basis for a "digital archive/library" that classifies and locates collection objects. This type of archive will display photo images and document content. It can further evolve into a specialized "Collections Management System" (CMS) database that follows accepted "best museum" practices. Other CarLibrary.org pages demonstrate and explain several types of computer software which can create a digital library or CMS. However, a well-designed inventory will show benefits at each implementation stage. The following recommendations are based on several years of personal experience to achieve an improved "archive" of books, documents and photos. These recommendations are also based on current digital archive/library practices, advice, documentation from professional digital library developers and archivists - and commons sense! These recommendations should help avoid "false starts" common when setting up a database or collection system - where initial poor design results in a re-design and repeated "data entry". The processes will also make use of any identifying information (metadata) which may already be "on/within" digital files. A further objective is to make use of professional and practical library/archive standards so that the collection - and its object/documents/photos - can be shared usefully with others. This web page covers the following topics:
Why should a collector or historian want to be better organized or work towards an "archive"? Some car hobbyists and collectors like to work and collect solely for their own pleasure. Other collectors/historians want to share their "collection" with others. Most collectors/historians enjoy seeing other car collections/museums, their libraries and other related material. Automotive (and other) collections can be "organized" in many different ways and from "casual" to "obsessive". Traditionally, file folders and cabinets are used to store documents and photos. Artifacts (including spare parts), books, magazines may be on shelves or in boxes. For the collector who enjoys his collection alone, improved organization can make all of this material easier to access. Further, better organization may show relationships between some objects that is "new knowledge" - such as finding old magazine articles on a marques being collected or discovering commonality of a part to several manufacturers. For collectors who plan to share their collected material and search for photos, documentation or literature from others, organization is very important. A collector may be willing to sort through semi-organized material a few times looking for something particular, but such searches through archives of documents, photos or books are not helpful for any practical exchanges of information. This also applies to museum professionals seeking to improve their institution practices. Digital photos and digitized documents have greatly complicated the organization task - these likely will have cryptic file names, are only viewable on a PC/Mac or other electronic device and can be overwhelming numerous and unorganized unless systematically standardized. To summarize, a collector's goals may include:
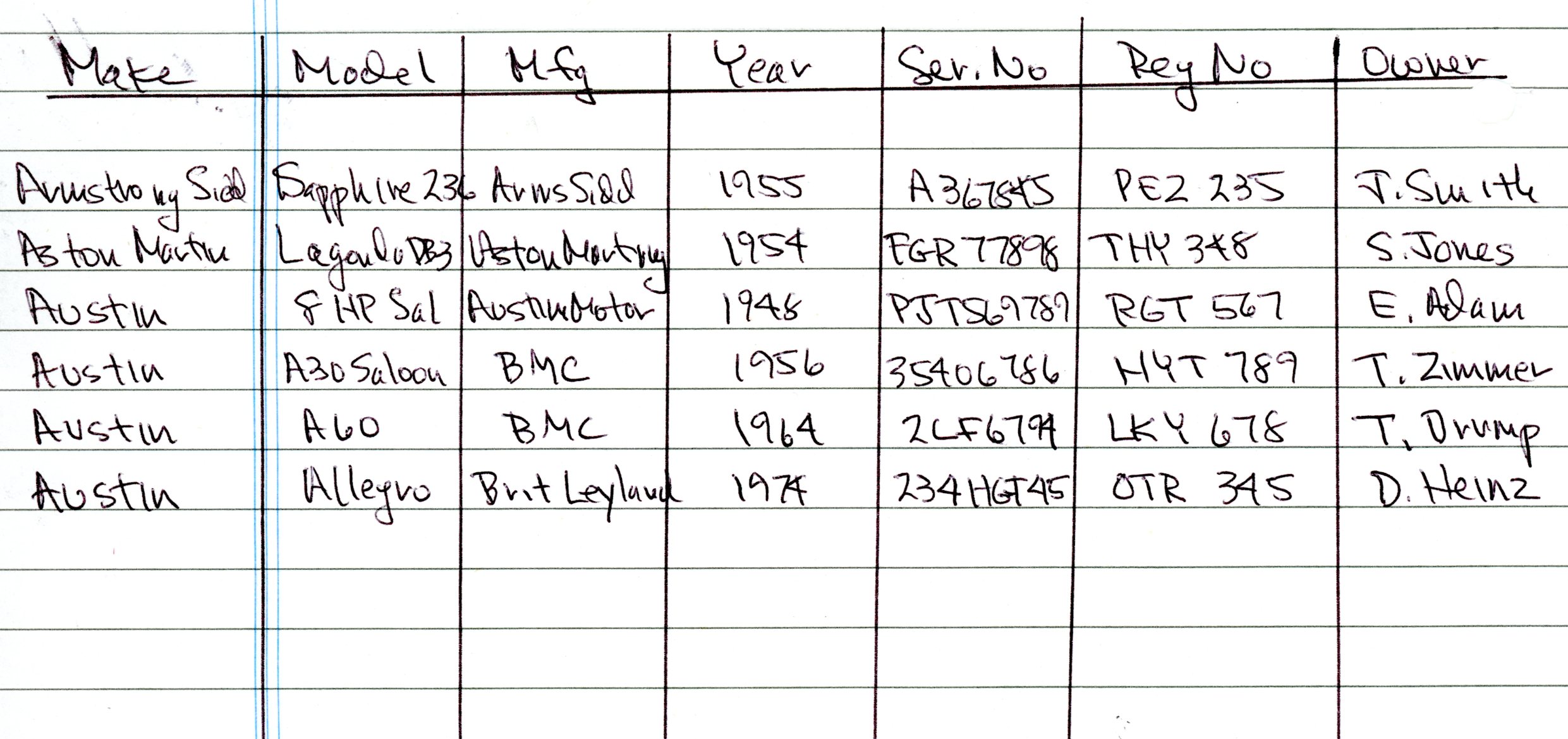
An initial step is recognizing that many of the collection's assets are physical items! This may seem elementary, but it may help make a better understanding of the first steps: Step One - Create an Inventory - Objects Because this topic is about car collections, make a list of the relevant cars. Car parts can be added on separate list of using categories ("fields") described below. A list can be as simple as a hand-written one, in a notebook:
A list such as this, using rows and columns, provides a good introduction to basic database features and is easily transcribed to a computer using a spreadsheet. Experience has shown that a spreadsheet (Microsoft's Excel, LibreOffice Calc, etc.) is an excellent method of recording inventory items. (Further discussions will refer to Excel as the spreadsheet program.) For many collectors, Excel will be all that is needed. Some collectors will need a more capable inventory system, using database software (File Make Pro, Microsoft's Access) - a collector should expect an easy import from Excel to a database program. Commercial and open-source software systems designed specifically for museums and collections - Collections Management Systems - should also allow a direct data import. However, the "data" in well-designed spreadsheet can be enhanced and recognized as "metadata" for each collection item. These topics are explained in the next topics in this series of webpages. Whether used "as is", exported to a database or later used for its metadata, spreadsheet data can be recycled - this will reduce or eliminate the need for new data entry and postpone decisions on alternatives to original spreadsheets. If there is a printed or card-file inventory for the collection, possibly the cards can be scanned and converted (Optical Character Recognition, "OCR") into data that can be imported into a spreadsheet. If an older different database program has been used, such as dBase, FoxPro or File Maker Pro, etc., the data can also be exported into a file type compatible (usually Comma Separated Values - "CSV") with the spreadsheet of choice. What is a "well-designed" Excel file? Without getting too deeply into database file design, each item (for example, a car, a car part, book or photograph) should be on a single Excel row. Each characteristic, "Make", "Model", "Year", etc. should be a separate column heading. In database terminology, each row is a "record" and each column heading is a "field". Each type of asset - cars, books, photos, owner records - should be listed in a separate Excel file. If any data element repeats frequently, such as "General Motors Corporation", for the Manufacturer, it can be considered for placement in a separate table/file - this is "database normalization", which will be further discussed below. This is a basic example of a table/file for cars:
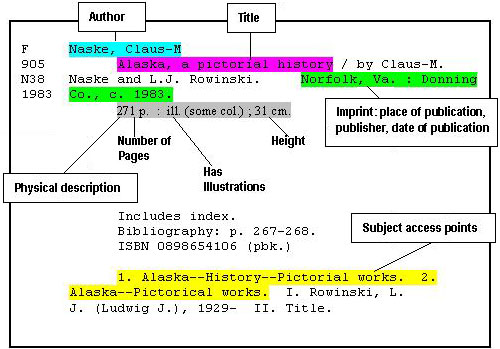
What is the "Accession Number" as used in the first column? This Wikipedia definition states: "In libraries and museums and other archives, an accession number or catalogue number is a unique, usually sequential, number given to each new item acquired, as it is catalogued." Why should any (small) collector or historian care about this museum practice? If future data uses are anticipated, when there is a need to match a photo (physical or digital), a document, book or a part to a particular car, this relation can be made with accession numbers. If the car(s) have an accession number, this will be the basis for making a relation (cross-reference) in a database or digital archive. Or in any other Excel file! If the collection inventory initially creates a unique numbering system, much effort is later saved! Museums have long used a system of accession numbers based on the acquisition date and hand-written log books to establish provenance. This may not be important to a car collection and the date any item was acquired may be difficult to establish. The author's sample Frazer Nash collection uses a numbering system based on the "best guess" of year and month acquired, with necessary digits after that. A book acquired in December 1975 could be therefore "75.12.1" (or "1975.12.1" may be necessary for a collection with items spanning more than 100 years). In the this Frazer Nash collection, cars are assigned an accession number first using the year of manufacture followed by the serial number. For digital assets, such as photos or scanned documents, an accession number system can also help identifying multiple copies at different resolution, perhaps from later, improved scanning. Although best museum practice does not recommend using suffixes on accession numbers, copies of an original document or photo could be "2012.12.1a", "2012.12.1b", etc. Digital scans can also have a unique accession number and be "related" back to the physical object. The Accession Number should be recorded (pencil) on each document, photograph and book. Perhaps also "on" each car or other object! It is good practice to use a numbering system on old photographs even prior to starting the actual inventory. Step One (continued) - Create an Inventory - Books Cars and vehicles may seem to have categories that are obvious to a collector. What categories should be used for books, magazines, and magazine article? Well-established library practice presents good examples, as shown on a sample card from a traditional card catalog:
This data also can be recorded in a spreadsheet file:
This sample book data and file above was created and later enhanced through the use of LibraryThing.com; this Internet service is discussed in other topics/webpages. Step One (continued) - Create an Inventory - Photographs and Documents Photographs and documents should use an inventory format similar to that of books, but the categories may not be readily evident. Caption (description), date, location, and photographer should be the minimum data for a photo. "Step Three - Metadata" below suggests other standard categories for identifying these items.Collections/museums following "best practices" should consider creating a document (catalog sheet) on paper for individual (or groups of) photos and documents that will index the physical file system or other storage. This document can be viewed as a true "archive backup" which will likely survive any evolution of a computer-based inventory that may become obsolete. A duplicate of these inventory documents should be kept in an alternate, secure location. Identifying and managing the digital scans of these photos and documents are also discussed below; if the initial emphasis is on the collection's "physical assets", the management of the digital representations (computer files) may be more clear. Step One (continued) - Create an Inventory - People and Events Lists of people, such as contacts or former owners of the car(s), can be recorded to an Excel file in "standard mailing list format": last name, first name, address, etc. Similarly, if there are lists of shows, rallies, races or other events that relate to the car(s), these can be recorded in a separate Excel file with "event name", "event type", "date", "award", etc. as the categories/fields. Step Two - Review and Improve the Inventory Files Each Excel file (table) should be reviewed for consistent and accurate data. As mentioned above, data redundancy can be lessened by the practice of "normalization". From Wikipedia: "Database normalization is the process of organizing the fields and tables of a relational database to minimize redundancy and dependency. Normalization usually involves dividing large tables into smaller (and less redundant) tables and defining relationships between them. The objective is to isolate data so that additions, deletions, and modifications of a field can be made in just one table and then propagated through the rest of the database via the defined relationships." In practice, this is not so critical for most Excel files because copying cells is easy and "data storage" is cheap. Using an Accession Number for each item (or for the data entry line of a person's name or business) makes relations (cross-referencing, linking) of items much easier. For example, it is easier to make Excel/database entries for 40 photographs of a particular 1952 Frazer Nash with Accession Number 1952.168 rather than repeat "1952 Frazer Nash Mille Miglia S/N 421/100/124" 40 times! This is especially true if the Excel history file (or actual archive/collection) contains information on 11 different Frazer Nash Mille Miglias! Because combining and splitting cells, creating consecutive numbers and moving rows and columns are normal operations in Excel, Accession Numbers can be added at any time and normalization can be improved. Using consistent and standard descriptors is important. Is it a "Chevy" or a "Chevrolet"? Is the company "GM", "General Motors Corporation" or "General Motors Company"? This is an issue that has concerned librarians almost since the first library! A resource to solve this issue is "name authorities". One source of a "name authority" is the Library of Congress Authorities. For example, the Library of Congress recognizes both "General Motors Company" and "General Motors Corporation" as authorities at different times. The collection should strive to "get it right" and create files and descriptors that are "standard" and can easily be searched by others - this "name authority" source (and others) should be consulted early in the inventory creation process. There are similar authorities in other countries and there is an international service also, the Virtual International Authority File (VIAF). The Library of Congress states "Voisin, Gabriel, 1880-1973" is the authority for this early French car manufacturer. The VIAF agrees, with cites from France, Germany and the Netherlands. LibraryThing.com can provide a shortcut to improving a books' inventory. This is an online service that allows free entry of 200 books, with unlimited entry for $10/year or $25/life. One-by-one entry of books is simple, with only a partial author's name or title usually needed to bring up (match) a full set of data on the particular book from more than 600 worldwide libraries. When the match is made, the book in your online "library" will have extensive data, such as the ISBN number, Library of Congress number, etc. The service provides a batch entry (import) from an Excel file (converted to CSV) and a similar export. Therefore a "round trip" of an Excel file of books through LibraryThing will result in an excellent book inventory, with good descriptors for each book. Resist over-planning, hoping for a near-perfect system. Perfection is not necessary! Inventory files can always be improved, but when a collector reaches a stage where he/she thinks (and perhaps after a third-party review) the (Excel) inventory is reasonably good, the collector should realize that a new digital asset has been created - the inventory file(s) are the assets and the item descriptors (matched to the fields/column headings) are the "metadata" for each item. At this stage, there may be "enough organization" with the inventory lists for the collector's personal goals/purposes. If so, such a collector is likely far ahead of most car collectors/historians! Also at this stage, the spreadsheet data can create a Greenstone digital library/archive using this open-source software: see Importing Spreadsheet Data Into Greenstone. Or continue to the following Step Three. Step Three - Metadata The common definition of metadata is "data about data", but Wikipedia provides much more detail and clarifies this common definition - reading this source is highly recommended. A traditional card in the (old) library catalog files was all metadata: book title, subject matter(s), keywords, author, date, publisher, etc. "Metadata" has been "around" for a very long time, but this nomenclature gained great recognition in the early (pre-Google) days of the Internet, as words/terms in specific categories were "embedded" in web pages, visible only when viewing the HTML code. This web page, for example, has "DC.Title" content="Archive/Collections Basics" near the top of the HTML code behind this page. Before Google used other classification techniques (including indexing the full contents of webpages) to refine searching, these meta tags were the only method to classify and search the Internet. Because "everything" is not yet digitized and fully text-searchable (difficult for images!), using metatags and searching through metadata will be important for many years. As an example of metadata, having "Aunt Sally's Ford" penciled on the back of an old photo is better than nothing, but a fuller description probably should state "Sally Brown", "1954 Ford Custom", "Seattle World's Fair", "May 13, 1962", "mother's sister". What is the "DC" in "DC.Title" above? It stands for "Dublin Core", a widely recognized standard set of metadata categories defined in a 1995 metadata workshop in Dublin, Ohio. You can consult Wikipedia for more background and the fundamentals of this standard, but it is more important to know there are standard categories for your metadata that will be used and recognized by librarians, archivists and software used to make digital libraries and archives.
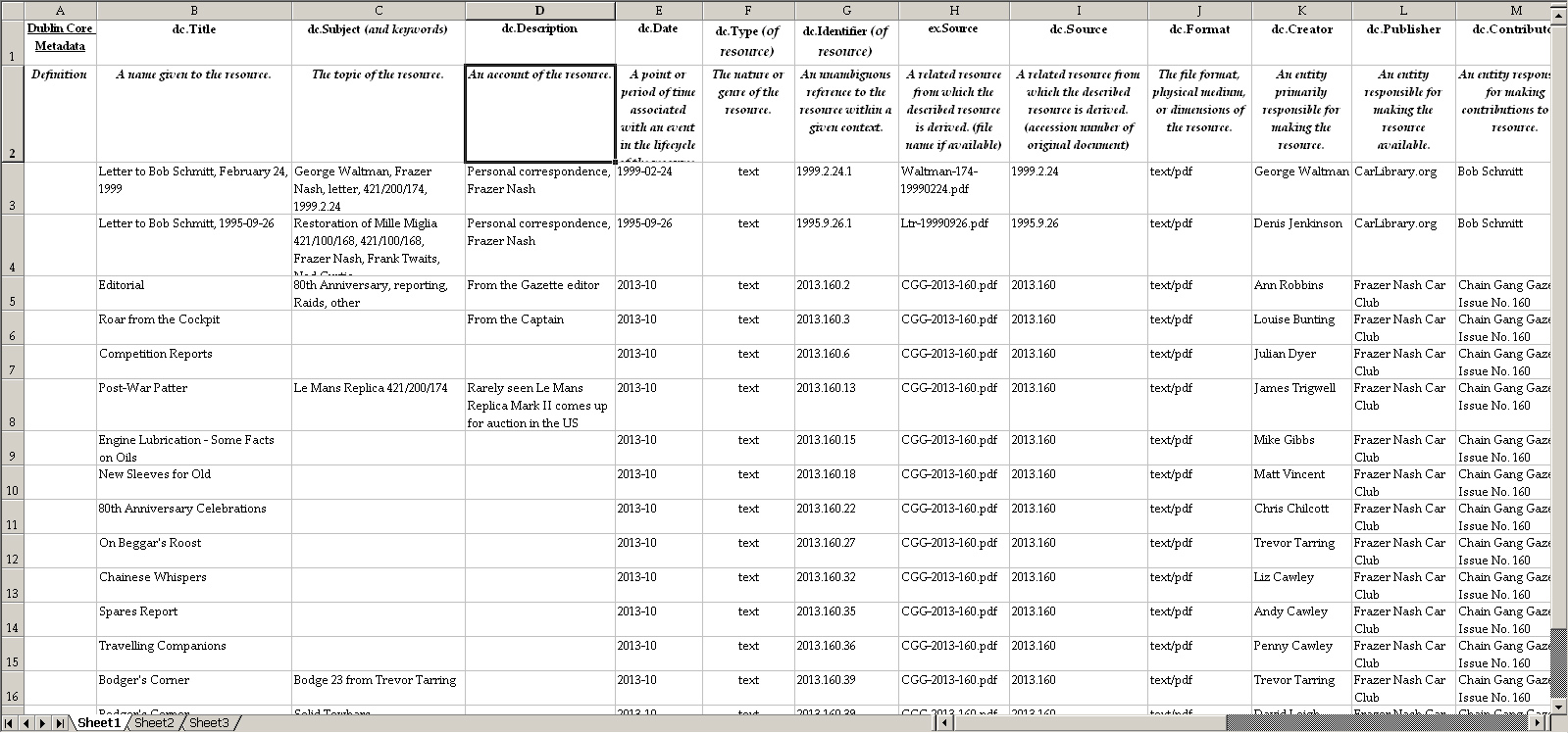
If the collection's Excel inventory has used consistent "descriptors" for its cars and other items, changing the column headings to the appropriate DC category above, may make the descriptors into the "Dublin Core" standard. Further, the Greenstone Digital Library software permits new metadata categories to be created, such as "car.Make", etc. Metadata can be "internal" or "external" to the item. The card in a library card catalog is "external" to the shelved book; the title, author, etc. on the first few pages of the book are "internal". Similarly, the data in the Excel inventory files are also external metadata. Other digital items, such as digital photographs (or the Excel inventory) may have internal "embedded metadata". For example. using the Excel program's "File" menu and selecting "Properties" will cause a name to appear as "Author" and a company name may appear as the "Business". Other Microsoft's Office software also similarly embeds metadata through the "File" and "Properties" menus. Many other digital formats have extensive metadata embedded in their files, but not readily visible. Step Three (continued) - Viewing Embedded Metadata Microsoft's Windows Explorer provides options to view embedded metadata in any file. In the "View" menu in Windows Explorer, there is a "choose details" selection. This opens up an enormous list of metadata that can be added to that folder's view and/or replace the existing file data that is the normal default. Changes made will remain for the particular folder being viewed when it is next opened. However, the Windows Explorer "menu" may be hidden by default. This link to Microsoft Help explains how to add the Menus - this is worth having! Go to the second tip under "To change advanced file and folder settings". When this is selected, there are checkboxes for options to open multiple windows and many other useful features. Alternatively, click the blue help/question mark on the top, far right when Explorer is open. This will open a screen that states "Working with the _____ folder". Further down this screen is a live link to "change folder options". Next, "click to open folder options", then the "view" tab at top. That opens a screen with many checkboxes for options. Select the second checkbox: "always show menus". Step Three (continued) - A Dublin Core Metadata Example The screen image below is a sample index made using the Dublin Core categories. The material consists of two items of personal correspondence and the articles in the "Chain Gang Gazette", issue #160, a publication of the Frazer Nash Car Club. This example is incomplete. (Note: "Subject" and "Description" categories are difficult to distinguish in spite of research on this issue. Perhaps more experience will bring clarity and "archive standards' to these categories.) The trial/test accession numbers for the Gazette articles are based on the year and issue number - the numbers are used for "source" and "resource identifier". The physical Gazette and the PDF scanned file use the same identifier. The accession number was extended to use page numbers for each article. The entire Gazette issue was scanned, yielding accurate text recognition with the ABBYY FineReader OCR software. This scanned issue was added to the Frazer Nash archive in Greenstone. An index exactly like, or similar to, this should be useful for many purposes. It may be too detailed a prototype Greenstone Frazer Nash archive, but it may be a good step if a professional Collections Management System (CMS) is planned.
click on image for full-size version Music (MP3) files will typically have embedded data for "Album", "Artist", "Date", "Genre". This is the source of this information on most music players - computers, tablets, phones. Digital photographs typically have hundreds of metadata items embedded, visible in photo editing software (Photoshop Elements) and photo organizing software (Google's Picasa). Documents scanned to PDF and other formats may have only a few items embedded, unless the operator and scanning software have taken active steps to identify the documents through metadata. Other software that will manage digital photos and metadata are DBGallery, Zoner Photo Studio and Breeze Browser. (Note: Google announced on February 12, 2016 that Picasa, its desktop photo editing and management program, would not be supported after March, 2016. The Picasa Web Albums, the online feature of this program, would transition to Google Photos. CarLibrary.org has recommended using Picasa for basic photo captioning and metadata tagging, including location tagging. "Desktop" Picasa will function indefinitely for this use. Software ("app") program recommendations will be updated as replacements become known.) 3. Other Digital Assets - Preparation for Archiving The topics and steps above are about the physical items in a collection. In this digital era, a collection is likely to have the digital "clone" of those items or unique digital objects, such as photo from a digital camera. While these are also "physical" in that they are bits and bytes on a storage medium, they are a unique collection category. What special steps are necessary for digital assets? File Naming: Digital photographs initially have cryptic (non-descriptive) file names. The choices for easier identification of these images are to re-name the image files (wholly or partly) or add metadata to the file, as described in the CarLibrary.org-Metadata web page. The program "ReNamer" provides a method to add more data to the file names in a group of image files, such as accession numbers. Google's Picasa can be used to add metadata to digital images one-by-one but the more capable ExifTool can add, delete, modify the metadata for a group (directory) of image files by "command line" operations. The ExifTool can produce a full list of image files in a directory with the metadata listed for each file. This list, with minimal further processing, can be directly imported into the Greenstone Digital Library software. The CarLibrary.org-Metadata web page describes steps for using the ExifTool. However if the image files use the "Enrich" function in the Greenstone digital library software, which adds (external) metadata to each image (or group of images) neither renaming or adding embedded metadata is necessary Should any of the re-named digital images include the same "description" as the actual object (car) or use the Accession Number of the object? For example, if the digital image is a photograph of a specific 1955 Chevrolet, the only good reason not to rename the image "1955Chevrolet_xxx".jpg is perhaps to preserve the identity of the original image/file. However, having a standard procedure to archive all unedited digital images to a separate storage location lessens this concern. Should the re-named digital images include all or part of the Accession Number of the original object? As an example, if the car has Accession Number "1975.12.5.1", should the digital image of this car be renamed "1975.12.5-1.jpg" (or similar)? The archive community seems to be split on this issue. One camp holds that every archived item receive a unique, consecutively assigned Accession Number. Another opinion holds using the original Accession Number with suffixes is acceptable. Digital File Preservation and Copies It is inevitable that any collection of digital images or scanned documents will have multiple copies of the original image or scan, perhaps at different stages of editing or with different resolutions, each created for a specific purpose. Confusion may be lessened by establishing a standard file storage and naming process. For example, all "originals" are stored in a specific drive and folder(s). All copies are named with a specific suffix, which can include letter codes to identify purpose and/or resolution. The Picasa digital photo editing/organizing program does not alter an original digital photo during its editing (cropping, etc) process until the image is exported to a separate folder or until a deliberate menu "Save" is selected. All edits are retained in a separate, proprietary file for each folder of images. The Greenstone program uses copies of images and documents for its "Gather" (import) function, the files are not moved from their original folders/drives storage locations. These Picasa and Greenstone functions - leaving original images unaltered - seem to conform to standard archive practice. These are tested recommendations for digital assets: Digital (and other) Photographs:
Scanned photographs and other images:
Scanned Slides and Negatives:
Scanned Documents:
4. References and Suggested Reading A free online training course, "Digital Libraries, Repositories and Documents" is very useful to learn terms, practices and steps to create a digital library. Regular reference to this site and its lessons can be very helpful. The module is described:
A comprehensive reference source is "How to Build a Digital Library, Second Edition" by Ian H. Witten, David Bainbridge and David M. Nichols. Reviews of this book note it is suitable as a university text for digital libraries/archives. About two-thirds of this book is an excellent introduction to the concepts, history and issues of digital libraries - all relevant to the tasks needed to manage a collection. The remaining parts of the book are good tutorials for the Greenstone digital library software. The author always has his copy nearby! Email me with any suggestions or questions! Bob Schmitt, rgschmitt@gmail.com |