Car Collections and Digital Technology
(Version 3.4)
|
(Click on logo to return to main page) |
|
Introduction: The Greenstone Digital Library software (open-source/free) from Waikato University, Hamilton, New Zealand, is very well suited to creating a collection's "digital repository" for the cars, artifacts, photos, books and documents - in, or planned to be in, a digital format. "Collections Management Systems" (CMS) is another category of software that can be used comprehensively for inventory and management of physical and digital assets. Commercial and open-source programs are readily available. Many of the preparation techniques discussed below are applicable to a CMS. Greenstone can create much more than a "library", but can make a "digital repository" for a Collection, Archive, Library or Museum (CALM). Only recently have managers, archivists and curators discovered that they have similar needs for organizing irrespective of the nature of their "items". A digital repository can be used as an internal reference by a curator on a single PC, for the collection staff on a network, or made available on the Internet, totally or as subset, entirely open or with access restricted to named users with passwords. Although there are other type of software, open source and commercial, which provide similar organization, search and display functionality, Greenstone is proven, professional and powerful. Using Greenstone eliminates some cost and training hurdles and makes the "first step" of repository organization very accessible to anyone with modest computer skills. This webpage provides a step-by-step guide to go from "chaos" to "organization" in a few steps. Step One has a few basic organization suggestions for putting the cars and "items" on lists. You may find that gathering, identifying, and roughly classifying cars and items is tedious and time-consuming, but this single step may be enough for your needs. Your entire collection (i.e. "everything") need not be included in Step One - items can be added later. If the benefits of Step One seem useful, your can move on to further steps with partial lists/inventory to create a Greenstone digital repository or you can focus on making a complete inventory of your collection. Step Two outlines the conversion of your lists/inventory into Greenstone and introduces terminology and tools to more completely classify vehicles and items. Step Three is an overview of Greenstone operations and features. This "how-to" webpage cannot replace a Greenstone tutorial (the Greenstone wiki has links to the tutorial and the lessons from 3 and 5 day workshops). There is a similar tutorial in the excellent book, "How to Build a Digital Library" (2nd edition); either tutorial has more than enough information to help you build a good digital repository. "How to Build a Digital Library" was written by Professors Witten, Bainbridge and Nichols. It contains an excellent background discussion and considerations for a digital library and a great Greenstone tutorial and reference. Step One - Building and Improving Inventory Lists This Step assumes you have some familiarity with Word tables or Excel files to produce lists/databases that can be imported into Greenstone. Although you can enter your collection data directly into Greenstone and thus avoid this step, experience has shown there are benefits from making lists:
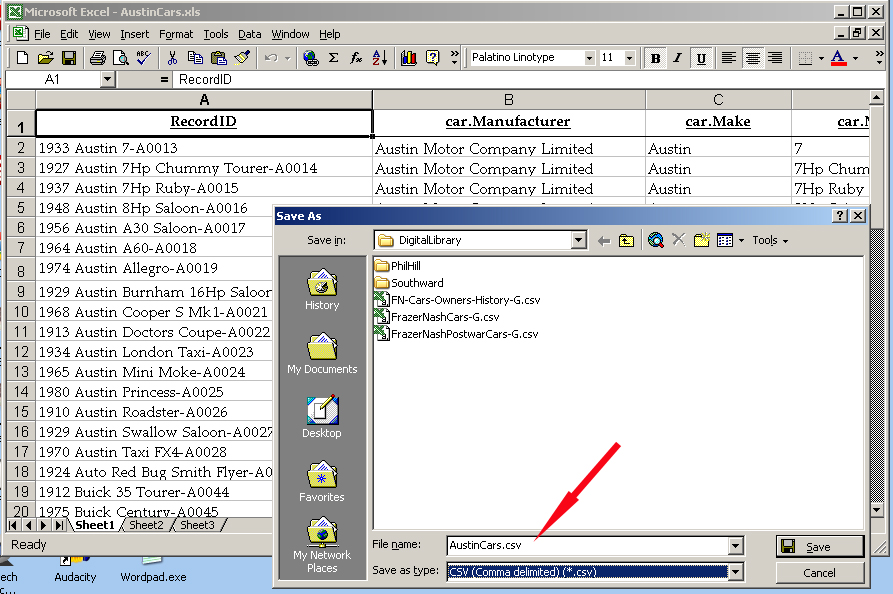
If you are using index cards or paper-based inventories (lists) for your cars, books and documents, these must be typed in Word or Excel (or scanned with OCR) to create digital files similar to this:
Note: In June 2013, the ExifTool was used to create an Excel file from the files in directories (folders) on a PC. See ExifTool - Reading and Writing Embedded Metadata, another page on this website. This is a great shortcut and time-saver! Identifying All Objects Uniquely Does the car collection use "accession numbers", "object ID" or "catalog number" for the cars and items in the collection. What are these? An accession number is a standard museum procedure, used for at least 150 years, to uniquely identify every object in a museum. This is traditionally done in a ledger book for permanence and and establish ownership, but these ID numbers should be used in a digital repository also. In the example above, nothing else in this collection will have accession number "1987001" except the Austin Allegro car. Greenstone provides an easy method to relate a document to a particular car, such as the Austin Allegro, so a photo of that Austin may have 2008003 as an accession number, but the record for the photo can point to "1987001" also. If you have not yet set up a system of unique identifiers for your collection, this can be done in Excel in a semi-automated manner. Further, you should make the first column entries of your Excel file a unique, but descriptive identifier, such as "1974 Austin Allegro-1987001". In the examples in Step 2 below, this will be the "RecordID" column heading. These entries will show up immediately in the Greenstone file, making the collection records easier to use. These entries can be created by combining cells with the Excel "concatenate" function. In the example above, the "dc.Description" cell and the "Accession No." cells are combined to make ""1974 Austin Allegro-1987001" as a new "RecordID" entry. Field Names/Metatag Categories The table above is an example with a subset of all the "fields" or column headings; an actual table for the cars may contain all of these:
For books, photos and documents, the standard "Greenstone" (Dublin Core) column headings are:
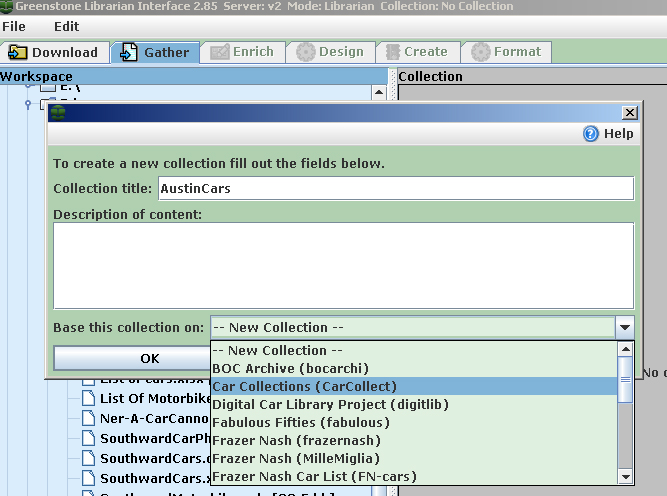
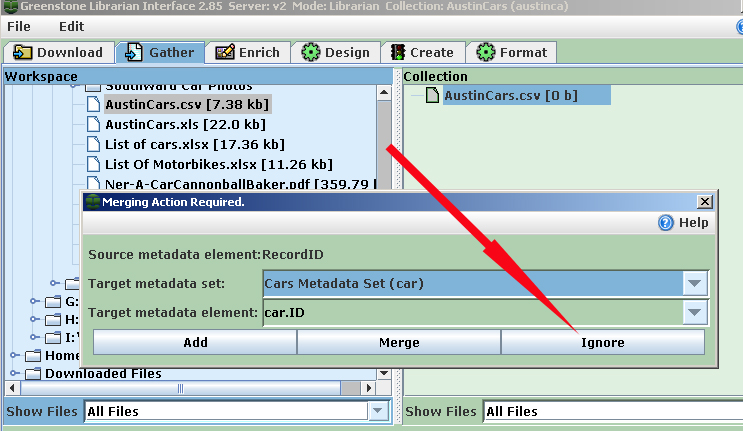
The "dc." part of the heading shows these are standard Dublin Core identifiers. As you create the files for books, photos, etc., it helps to have some knowledge of digital library classification techniques. "Metadata" and "meta tags" will be explained more fully in Step Two, but now you should know that the cars and items are classified by metadata: "data about data" or structured information that describes, explains, locates, or otherwise makes it easier to retrieve, use or manage an information resource, especially in a distributed network environment like for example the internet or an organization". Classification Introduction Before attempting to "classify" beyond Title, Creator (author) and Description, some research or consultation with a librarian is useful. As a first step, look at the description of the "Dublin Core" a standard for digital metadata. Next, check the official Dublin Core website, a good starting point, especially topic 4. "Elements" at the bottom of that webpage. Even the basic categories such as "Title", "Description", and "Subject and Keyword" can be confusing and tedious to correct after import to Greenstone if there are many records. It's best to get it (mostly) right in the beginning. But avoid getting too deep in research: "The Perfect is the enemy of the Good (enough)" - Voltaire How Many Records? How many records should be created? If there are no digital files and the collection has 50 cars, create records for all. If you have about 100 photos or books, make records for all. For larger quantities, make about 30% records of all items. If you have a Word table or Excel file of all the cars, improve it as much as possible, using the fields listed above to make it as complete as practical for an import. The "fields" in Word or Excel become "meta tag" categories in Greenstone. Once the "Austin" car make is imported into Greenstone and in the digital repository, the term is available in a pick list to classify any other Austin that is added, or any book, photo, document with Austin content. Although the examples above seem to show that the "cars" table is different from the "photos, books and documents table, a single table is all that is needed. The Greenstone car collections created to date have added the "car" metadata categories to the Dublin Core categories and a single collection is the result. You can, however, import separate tables and combine them in the final Greenstone collection at any time. Import/Backup to Access After you have created an Excel file, consider importing it into the Microsoft Access database program, or similar. Your data will be more secure (harder to delete inadvertently) and Access will give you excellent reporting (print or online) and query abilities. Files (tables) can be linked together to make a potentially very powerful and useful relational database. Examples of Access databases for car collections, linking to car owners, events and other historical data can be found on this related webpage. The "RecordID" field you created, described in the previous paragraph, can become a key index. Examples of using Access are on the Car Collections, Car Clubs and Databases web page. Step Two - Importing the Inventory List into Greenstone The step assumes you have installed Greenstone on your computer and have used a tutorial to create a simple collection. These are the fields/categories that have been used used in the digital car collections created with Greenstone:
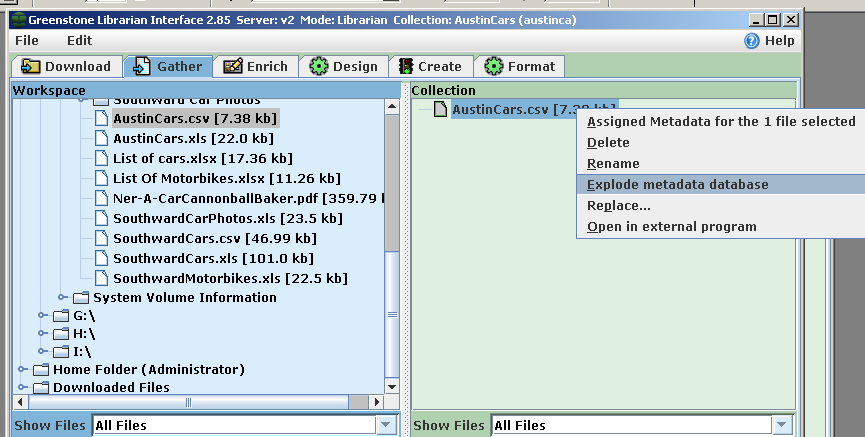
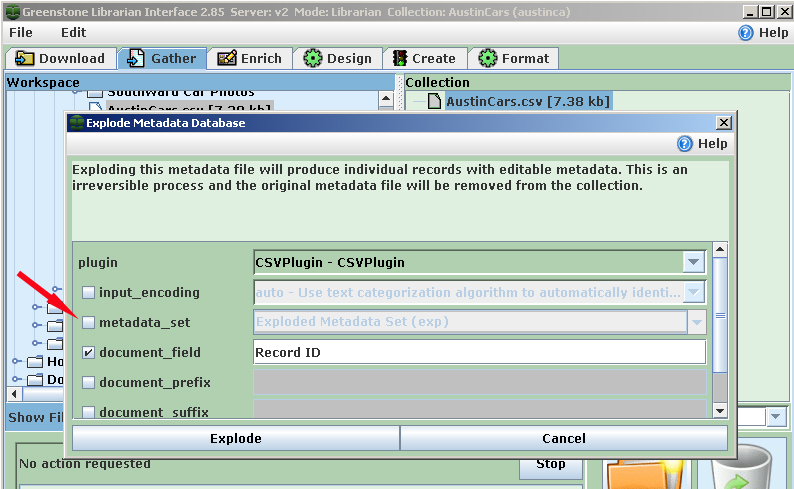
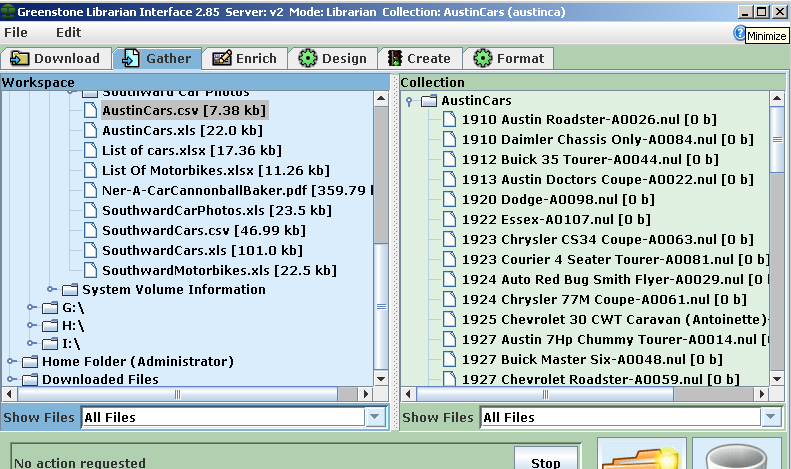
Note that the Excel file destined for Greenstone does not initially need to have entries for all of these Dublin Core metatags; metatag data can be added after the import as needed, directly in Greenstone. New metatag categories can be also created, such as "item.xxx" which could be useful to add physical attributes in an archive collections. New metatags should be added to Greenstone before the import. This process is described below. The "mapping" of car collections Excel file to the planned Greenstone collection is very easy - just rename your column headings to the relevant Dublin Core element or to a new metatag category you plan to add to Greenstone. Adding Metatags to Greenstone There is a Greenstone tutorial which describes how add new metadata elements by the Metadata Set Editor. Either use this approach or click on the "Manage Metadata Sets box in the lower left when you are in Greenstone's "Enrich" panel. For the the imports of the Excel example files shown above, a metadata set was created: "cars.xxx". For a collection that was primarily an archive inventory, an "item.xxx" metadata set was added. "Exploding" (Importing) Your Database In Greenstone, "importing" an Excel file/database is not very difficult. This process will create a (nul/empty) records from each record in the Excel file. Each record's data elements will become a metatag, ready to be used to identify/categorize each car, or related document, photo or other digital item. The Excel file must be converted to a "csv" format and then "exploded" in Greenstone/ Not to worry, it's safe! A Greenstone tutorial explains this - on that page, follow onwards from step 15. An Excel file cannot be "exploded" directly, but such a file is easily saved as a "comma-delimited" (Comma Separated Values, "CSV") file.
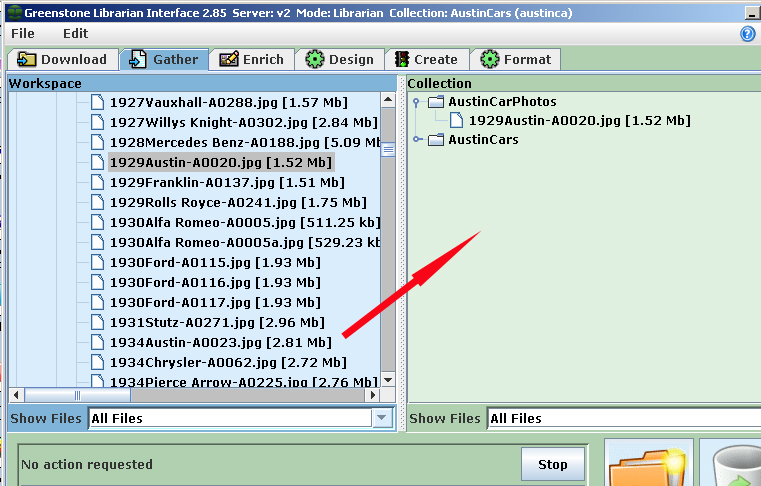
Step Three - Using Greenstone Functions If your import was successful and you understand how this limited set of records forms the "outline" of the digital repository, you can continue adding more Excel files (convert to "CSV") for further imports until all vehicles are in Greenstone. Adding Items Here is an introductory video which shows the basic steps to add photos, documents, etc. to the collection that has been just created. This video uses the "Frazer Nash" collection, but the steps are the same for any collection. A second video (11-minute "how to" add records) shows photographs added to the Frazer Nash collection, metatags added to each of those photos and briefly shows how the Excel source for the "Frazer Nash Owners" collection was imported to Greenstone. This is the same operation that this webpage explains above. Classification Similarly, you can can create Excel files for your books, documents and photos. However, as noted on other sections of this website, "classification" for books should be done to "standards" for at least two reasons:
Classification is a skill normally requiring training and experience, but the Internet provides help. One source is the LibraryThing online service, which is available free for up to 200 books. If you simply add collection books to a personal library, standard classification data will be added automatically. The books in LibraryThing can be exported to a "CSV" file, which, as we learned above, can be imported into Greenstone and "exploded" into the collection outline, with full metadata. For example, the 1952 English book, "British Motor Cars" (which has a good section on contemporary Austin cars) was taken from a bookshelf, quickly found through LibraryThing, added to a "personal library" and then the entire library collection (only 12 books!) was exported to a cvs file. Extracted Metadata Greenstone will also extract metadata from almost all digital files. For digital camera images, this is the "EXIF" metadata which show data such as a photo's creation date, camera used, settings, etc. Although all of this data does not seem important, the original photo creation date also can be very helpful. There are guides to "metadata" and "embedded metadata" on other parts of this website; check the Table of Contents! To be continued! The work to complete your new collection has only just begun! If you would like specific help with your Excel file, send it to me by email (all or part) and I'll send you suggestions or make the actual import to a Greenstone collection. All will be volunteer work, until I feel fully qualified to charge for services! September
27, 2012
|