|
|
|

|
|
CarLibrary.org - The Frazer Nash Archive
|
|
|
|
|
|
July 8, 2020 Background More than ten years ago, Microsoft's Access 2000 database software was used to make a Frazer Nash "digital inventory/archive" of photos and documents. It was more "inventory" than "archive". After experience with the (open-source) Greenstone Digital Library software, this program was used to create a Frazer Nash digital "collection" of documents, photos and other items. Later, the Greenstone "export" function was used to produce and distribute 50+ DVDs with sample Frazer Nash historical data, categorized for searching and display. Objectives This project was intended to start a framework of a Frazer Nash digital library that others, with more experience of digital libraries, Frazer Nash history and project management, could improve over time. A digital library or a car history database should always be dynamic and never truly "complete". However a long journey must start with a first step - hopefully this is a valid path! The sample Access database is described on this CarLibrary.org webpage. A complete list of all Frazer Nash cars was later added. Issue: should GN and Frazer Nash-BMW cars be included? If so, what is a source for this data? The Frazer Nash Digital Library - First Trials 2011 The first Greenstone "collection" was made using about 100 Frazer Nash items: photos, documents, articles and website references. However, there was some uncertainty when classifying these items. What distinguishes a "title" from a "description" or a "subject and key words"? What are the proper terms to use in each? Classification was first made on a common-sense basis, but would these classifications and terms be clear and useful for any user of the collection? What will result if the collection was exchanged or combined with another digital library? Would the "subject" be the same as another collection's "description"? When it became evident that this was an issue that librarians may have faced for hundreds (or thousands?) of years, this need required research into "standards". An initial question: "What is the 'proper' heading to use for Frazer Nash cars?" was partly answered by the Library of Congress Subject Authority File. This implies that "Frazer Nash automobile" becomes the "subject" in the Frazer Nash digital library. In the Greenstone program, this would be a Dublin-Core entry "dc.Subject and Keywords". The Dublin Core metadata standard "Subject" is defined as "The topic of the resource". It's assumed that other libraries do not deviate too far from Library of Congress (LOC) definitions. Because Greenstone also allows multiple, separate entries for any classifier, it seemed worthwhile to discover what term would be used for the "subject" of a book exclusively on the Frazer Nash cars by the British Library. The subject classifications of "Frazer Nash automobile" and "Sports cars Great Britain History" are used by the British Library for Frazer Nash books by David Thirlby and Leslie Jennings, but not consistently. The Library of Congress also has a "Name Authority File" for personal names. It includes an authorized version of the name, alternate versions and documentation for the selection of the authorized version. Searching for "Frazer Nash" and "Frazer-Nash" only found "Frazer-Nash Consultancy Limited" as a "corporate name". The same search in the British Library returned NO results. What has happened to Archibald (Archie) Frazer Nash? Both of these omissions require follow-up. The LOC Name Authority was also checked for "AFN Ltd." This listed the recognized "Corporate name heading" as "AFN Ltd." with "Variant(s)" listed as "A.F.N. Ltd." and "AFN Limited". See the LOC reference.These
recommended category entries are part of the "controlled vocabulary" for a
classification system.
As background - the LOC established in the late '60s, the MARC
(MAchine-Readable
Cataloging) which is "a data format and set of related standards
used by libraries to encode and share information about books and other material
they collect". Because of MARC's complexity, the "Dublin
Core" was developed in the '90s as a standard for digital metadata
("data about data" or "“structured information that describes,
explains, locates, or otherwise makes it easier to retrieve, use or manage an
information resource, especially in a distributed network environment like for
example the internet or an organization"), The "Dublin Core" classification system used by Greenstone is
relatively simple to understand and implement; it is explained elsewhere
on this CarLibrary.org website Each of the
Dublin Core elements are separate categories for classification, to be
filled with appropriate metadata. For the car-oriented digital
libraries, this project added "car manufacturer", "car
make", "car model", "car year" and "car
serial no", "car country", "car keyword" and
"car location". Other categories can be added if
necessary. Are the
Dublin Core categories and the suggested "car" categories
sufficient? What should be added? Other than the British
Library and the Library of Congress, has any organization (RAC?) established a
"controlled vocabulary" for an auto/vehicle classification system? Are there any Frazer
Nash Car Club members or member friends with library skills or experience? Further Progress - 2013 The
sample Frazer Nash collection was brought closer to classification "best
practices" and the remaining 1,000+ documents, photographs and
references are planned for addition to the collection (over time!) A
trial/sample/test Excel list of the Frazer Nash cars was used for import trials into
Greenstone, to form a standard for later entries into this collection.
This list of all Frazer Nash cars was greatly improved in July, 2013. This
is
a video
progress report on the very successful import trials on January 9, 2012. The video from January 9 is Part 1. Part
2 is an 11-minute demonstration on adding records (photographs) to the
Frazer Nash collection and selecting metatags for those photos. The video
also shows the Excel source for a test Frazer Nash "owners" collection and
explains how that Excel file was imported to Greenstone. Although
many of Frazer Nash resources are in paper format, additional
scanning is not planned until it's known if these documents are unique and have not been
already scanned by the Frazer Nash Archives. The
Frazer Nash
"collection" should sufficient to evaluate the value of Frazer Nash digital library.
DVDs that demonstrate this
fully-contained, self-running library were sent to two Frazer Nash Archive trustees. In
May, 2012, the Frazer Nash
archive/library/collection was
put online to allow
wider Club member evaluations and feedback. User authentication and password
security can be added, if requested. In
July, 2013, after much volunteer experience with a car museum selection process
for a Collections Management System (CMS), a few "best practices" of
museums and archives were adapted to the Frazer Nash archive on CarLibrary.org. When
(and if) the Frazer Nash Car Club thinks the digital library (or the
Access database) is useful for organizing the Frazer Nash Archive and
any future contributed material, current versions of the Greenstone and
Access material will be sent to the
Club. If the Club takes a different path, a
digital library of personal resources will be maintained 2014
Activity An
early Greenstone collections/archives made was for the Frazer
Nash. Later, it was based on an imported
(exploded) CSV file of all the pre-war and post-war cars, about
440 cars (including "replicas"). The archive also
contains about 120 objects, consisting of photos, documents and
sample web pages. These objects were categorized in
Greenstone with the standard Dublin Core metadata categories,
plus author-created car-specific categories such as "car.make",
"car.year", etc. Based on lessons learned
through work on Digital Asset Management systems (DAM) and Collection
Management (CMS) systems, the
archive was upgraded with new digital archival techniques. However,
there is very little difference visible
to an end-user. These changes improve searching and make
the addition of new
material more rationale. Also the Frazer Nash archive
is closer to
"best practices".
These
are the types of improvements to the Frazer Nash archive:
D. Frazer Nash Raid to New
England - Creating Captions and Car IDs Using Embedded Metadata
Section
D describes the first use of the ExifTool to efficiently put
metadata into a group of photos from an Excel spreadsheet
(exported to a CSV file). This should be very
useful for archives with many digital photos which are partly or poorly
identified.
The
initial list of Frazer Nash cars in the archive had a simple numbering scheme - the first
Frazer Nash built is "F001", the next one is
"F002", etc. Museum and archives practices
recommend an "accession number", which should be
in the first section the year an object
enters the collection, and then just serialized for
each object after that. Multiple objects entering in a
group would get a third digit.
The
first Frazer Nash built in 1925 with S/N 1008 is now assigned
"1925.1008". None of these cars actually
"enter the collection", but this combination of year
and chassis number seems to be a practical
approach. Postwar cars have serial numbers such as
"421/100/168". The last three digits are
uniquely adequate and easily remembered, so a specific car built in 1952
becomes "1952.168"
Other
resources - photos, documents, books - will use the archive
convention if the "collection entry date" is known and
meaningful. Most frequently, numbers are being assigned to
the date(s) best identified with the object. A photograph
or document from April, 1954 will become 1954.4.xxx with the
"xxx" assigned as necessary. A spreadsheet is
used record the file names, accession numbers and a description
of the item. As discussed below, this data will be used
eventually as "metadata" for each object/resource.
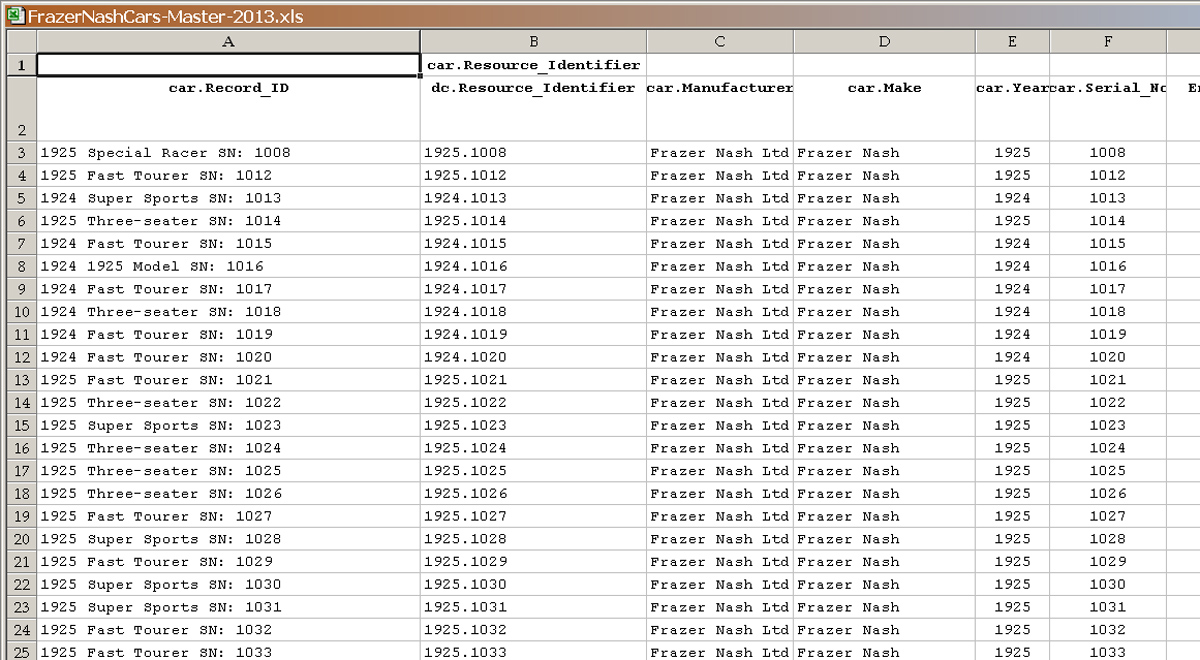
Figure
1 below is the master spreadsheet showing data for the early
cars and the assigned accession numbers.
Figure
1 - Extract from a Frazer Nash spreadsheet
This
spreadsheet was converted to a CSV file and imported into the
Frazer Nash archive (see
a guide to this process here) on July 20, 2013. It was imported, deleted, imported, etc. a few times
before achieving good results! As forecast, there are no
apparent changes for an end-user.
Other pages
on this website explain what is "metadata" as it relates
to digital resources. A complete and authoritative guide can be
found at: Dublin
Core User Guide. From this guide:
"A metadata record consists of a set of attributes, or
elements, necessary to describe the resource in question. For
example, a metadata system common in libraries -- the library
catalog -- contains a set of metadata records with elements that
describe a book or other library item: author, title, date of
creation or publication, subject coverage, and the call number
specifying location of the item on the shelf." The linkage between a metadata record and the resource it
describes may take one of two forms: 1.
elements may be contained in a record separate from the
item, as in the case of the library's catalog record; or
2.
the metadata may be embedded in the resource itself."
Using
"embedded metadata" is the next topic. There
are many standard metadata classifications but the primary
one used by Greenstone is the "Dublin Core" which has 15 basic
categories:
Dublin
Core Metadata dc.Title A
name given to the resource. dc.Subject
(and keywords) The
topic of the resource. dc.Description An
account of the resource. dc.Date A
point or period of time associated with an event in
the lifecycle of the resource. dc.Type
(of resource) The
nature or genre of the resource. dc.Identifier
(of resource) An
unambiguous reference to the resource within a given
context. dc.Source A
related resource from which the described resource is
derived. dc.Format The
file format, physical medium, or dimensions of the
resource. dc.Creator
(author) An
entity primarily responsible for making the resource. dc.Publisher An
entity responsible for making the resource available. dc.Contributor
(other) An
entity responsible for making contributions to the
resource. dc.Language A
language of the resource. dc.Relation A
related resource. dc.Coverage The
spatial or temporal topic of the resource, the spatial
applicability of the resource, or the jurisdiction
under which the resource is relevant. dc.Rights
(management) Information
about rights held in and over the resource. Table
1 - Dublin Core categories defined These
categories were known when the Frazer Nash archive was created, but
their use was inconsistent. To better understand improving
their use, the Dublin
Core examples were reviewed. Specific examples in Table
2 below come from this Frazer Nash photo (Figure
2). Figure
2 - Frazer Nash Mille Miglia publicity photo, Duke Donaldson is the driver Dublin
Core Metadata dc.Title Frazer
Nash Mille Miglia publicity photo, Duke Donaldson is
the driver dc.Subject
(and keywords) Frazer
Nash, Mille Miglia, Duke Donaldson dc.Description Publicity
photo of Mille Miglia 421/100/168 in New York dc.Date 1952-10 dc.Type
(of resource) image dc.Identifier
(of resource) 1952.10.5.1 dc.Source 1952.10.5
(the accession number of the the photograph which was
scanned) dc.Format image/jpg dc.Creator
(author) Duke
Donaldson dc.Publisher Bob
Schmitt dc.Contributor
(other) -- dc.Language English dc.Relation 1952.168
(the accession number of the actual car in the
photograph) dc.Coverage 1952-1953 dc.Rights
(management) NA Table
2 - Frazer Nash Dublin Core examples Data
similar to that in Table 2 is already in the Frazer Nash archive for all the
objects and resources, but was not very well "controlled." To approach archival standards, many of the
terms should adhere to a "controlled vocabulary" from an
"authority. As described above, the Library of Congress Name
Authority File recognizes "Frazer Nash" as the preferred
term for this car and this project will use this as
part of a controlled vocabulary. No authority could be found for
John Stuart "Duke" Donaldson, the importer of several cars
and owner of the Frazer Nash car and team that won Sebring in 1952. In the original Frazer Nash Greenstone archive,
all the resources are
described and classified by "external" metadata, which are
stored by the Greenstone program as separate files.For the most part, the
work that was done to create this metadata is only useful in the
Greenstone environment, with some exceptions for specialized exports
of Greenstone files. Collection managers now realize there are
many benefits to "embedding" the metadata in the digital
objects, as this forms a link between the metadata and the object
that can only be changed by deliberate editing. Embedding
metadata is discussed elsewhere on this website with the
ExifTool and other programs.
(A recent, unreviewed video on getting started with the ExifTool
and GUI is here)
The
ExifTool (and its GUI) allow the metadata to be extracted to
spreadsheet compatible files. These, in turn, can be imported
to Greenstone or Greenstone archive can be built directly, using
only the embedded metadata. In summary - "type it once,
use it many times". One
initial decision is to choose which categories to use for embedding
data - there are hundreds, perhaps thousands! Picasa captions
are put into XMP and IPTC categories: "Description". Picasa tags (keywords) are put
into "XMP.Keywords" and the "DC.Subject"
categories. The ExifToolGUI was found to be
more flexible, useful and efficient than Picasa. There is some inconsistent transfer of
keywords between IPTC.Keywords and DC.Subject when using Picasa to
embed "tags". In
the ExifToolGUI program, a custom Workspace file was created to
embed metadata in certain Dublin Core, EXIF and XMP categories. The
ExifToolGUI will display metadata in PDF, Word and Excel files.
Although the the ExifToolGUI will write metadata to some PDF files,
expect to use
other programs (Acrobat, Lightning PDF, etc.) to embed metadata in
PDF files. Word,
Excel and compatible programs in LibreOffice and OpenOffice can
embed limited categories of metadata in the "Properties" menu choice for
"doc"
and "xls" files. Table
3, below, is the Workspace "set" (part of the "ExifToolGUIv5.ini"
file) to use for work on the FN archive, created by
much trial and error! Category
Code [WorkspaceTags] Table
3 - ExifToolGUI
Workspace for the Frazer Nash archive
Below
is the actual "WorkspaceTags" part of the "ini"
file that will produce the Workspace described above and shown
below. It can be copied and pasted into that corresponding
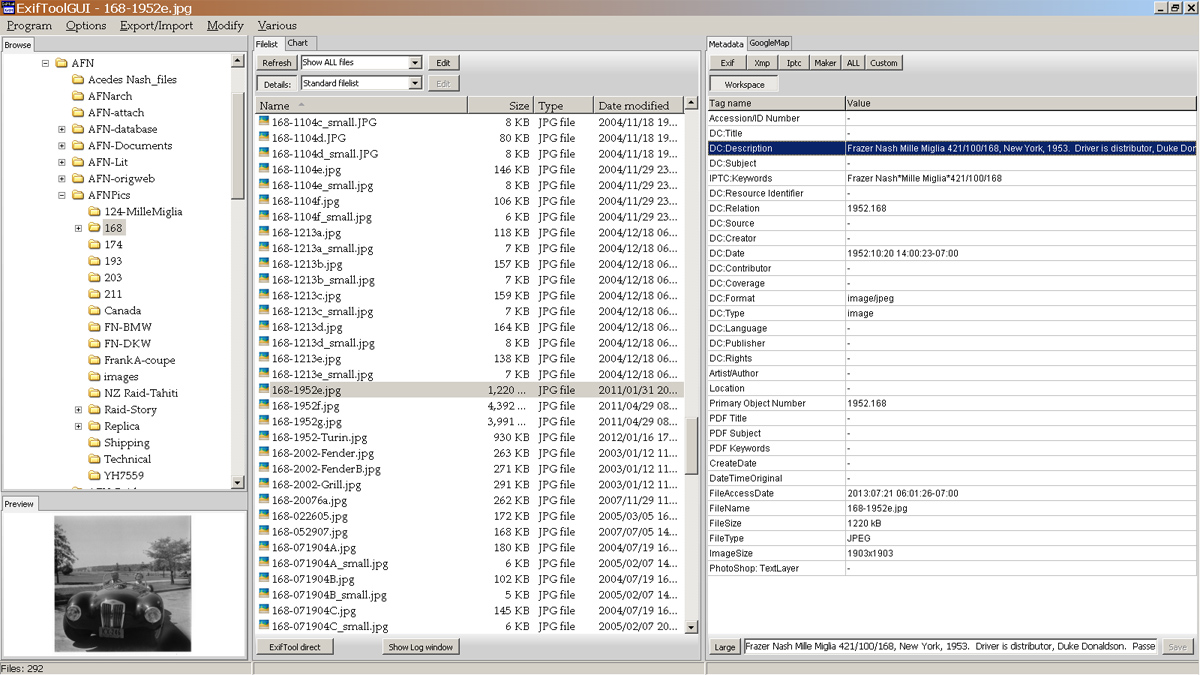
section any ExifToolGUIv5.ini: [WorkspaceTags] Figure
4 below shows what the ExifToolGui sees on the image file from
Figure 2 before adding the example data from Table 2 (above), as embedded metadata. Figure
4 - Screenshot from the ExifToolGui
The benefit of using a modified Workspace manager with
the ExifToolGUI is the efficient ability to embed user-chosen data in
digital photos and documents for later search and
retrieval. Further, extracting the data to spreadsheet
compatible files is easily done for many future uses.
Experience builds proficiency with the ExifToolGUI - it can
embed data in selected batches of photos quickly.
The original photo file date can also be preserved.
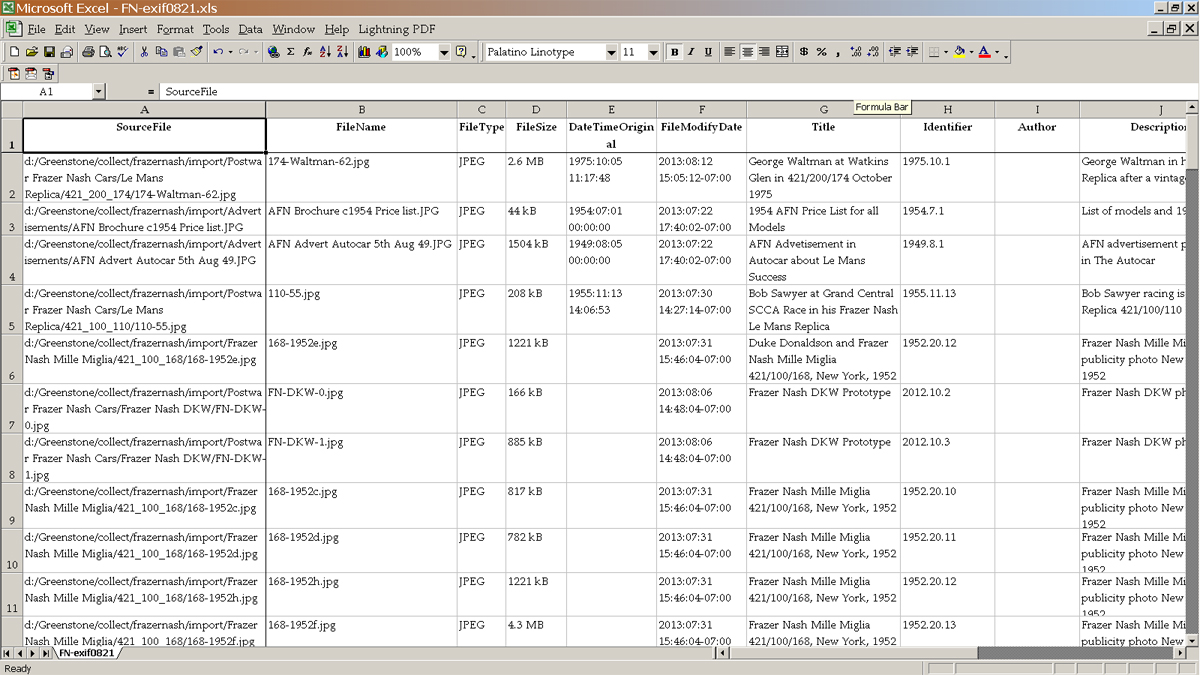
Figure
5, below, is an Excel spreadsheet made from ExifTool extraction of
metadata embedded in 200+ images and documents in the Frazer Nash
Greenstone archive. Although the "external metadata"
in the original archive was not changed, this demonstrates that the
title, subject, keywords, etc. embedded in these documents can also
be used for classifying and searching the archive and for any
other future need. Note that the "Identifier"
category (column) is the new accession number assigned to these
digital objects.
Figure
5 - Screenshot from an Excel spreadsheet of extracted metadata
This Frazer Nash archive has also embedded the "DC:Relation"/"Primary
Object Number" in nearly all photos and documents,
showing the relation of the digital object to
the physical object (primarily a particular Frazer Nash
car). This has the potential for very good, future
benefits. In
the example in Figure 4 above, the subject Frazer Nash car is
"1952.168". This technique can be used for collections
and databases that include lists of car owners, cars,
events and digital objects.
Based on more trials and feedback from reviewers
with the sample of photos and documents in the archive, this webpage will further make recommendations that may help
others making Greenstone collections.
D. Frazer Nash Raid to New
England - Creating Captions and Car IDs Using Embedded Metadata
Approximately 500 personal photos
were shot on the Frazer Nash
Car Club Raid to New
England, September 24 - October 3, 2013. Just over 400
were considered "good" and tagged into a Picasa Album,
then uploaded to a Picasa
Web Album. The ExifTool GUI was used to put captions in "DC:Description"
category; these appear as captions in Picasa on the
photos. The cars were
also identified with an assigned accession
number in the "DC:Relation"/"Primary
Object Number" fields. These accession numbers
were created as described above (e.g. "1952.196"), but a few cars could not be
identified with a chassis number, so numbers such as
"1937.UNK1" were assigned, for temporary, testing reasons.
Keywords and map locations were also assigned in the ExifToolGUI
and confirmed in Picasa.
Adding a unique accession number (in the "DC:ResourceIdentifier" category) for each photo
would be tedious using the ExifToolGUI, so the ExifTool "-tagsFromFile"
option, used from the command line. This option is described as using
data from a CSV file ("saved as" from Excel) to write to
entire folders of images as new (or added) metadata. After help from the ExifTool
forum, this command was successfully run. These were the steps:
1.The metadata was extracted
from the photos by running the ExifTool from the
(Windows) command line as follows to make a CSV/Excel file:
exiftool
-csv -r -FileName -FileSize -Title -Identifier -Description -Subject -DateTimeOriginal
-Relation -Keywords e:\DigitalLibrary\USRaid > Raid1030.csv This
produced the "Raid1030.csv" file, opened in Excel. 2. The metadata for each photo
(in the Excel rows) and in each category (in the columns) was checked. 3.
Specific data for
102 photos of individual cars was copied from the "Keywords" column to the
empty "Title" column. This set of photos was the initial
selection of photos to be added to the Greenstone archive. 4.
The Excel "data fill" function was used to create an "accession number" for all 400+ photos in the format "2013.9.1", "2013.9.2" etc.
in the "Identifier" column. 5.
Columns that had no new data were deleted, leaving only "SourceFile", "Title" and "Identifier". 6.
The Excel file was saved in the "CSV" format, using a new file name: "Raid1030input.csv". This was done to prevent confusion with the CSV file which extracted the metadata from the photos. 7.
A command window was opened and the "e:\DigitalLibrary\USRaid\"
drive and directory for the photos was maneuvered to. 8.
This ExifTool command was entered: exiftool -csv=Raid1030input.csv -ext jpg -v2
e:\DigitalLibrary\USRaid\ 9. Success!
The accession numbers were added to all 405 photos as
"Identifiers" and the 102 individual car photos now had
"Titles". The ExifTool had backed up the original photos
with an added "original" file extension. 77
of the 102 photos were further selected and added to the Frazer Nash
Greenstone archive. Only a single Greenstone item of
"external" metadata was added in
the "DC:Description" category at
the "folder" level:
"Frazer Nash cars on the Raid to New England, 2013"
using the Greenstone "Enrich" function. The
Raid car photos can be
reviewed in the Greenstone archive in the "titles" browsing tab by looking for the
"year of manufacture" of any car; it's the last tab segment: "0-9". One
anomaly was noted in the displayed "Document/photo date"
field for some Raid cars - the date of the most recent photo
modification (when photos were resized smaller for this archive by an export
from Picasa) is displayed. For other cars, the preferred
"DateTimeOriginal" is shown. Review of the
metadata in
Greenstone shows "DateTimeOriginal" has not been
consistently extracted from all files; this is an issue for further
investigation. To
provide another method to find the Raid cars, the
Greenstone "Create" function was used to add the metadata category
"ex.XMP.Relation" to "car.Serial" as a
search index.Because this archive primarily holds digital
objects classified with metadata originally imported as
Greenstone "external" metadata, "car.Serial"
is on nearly all these original objects. The Raid cars
embedded field "Relation" is now the "accession
number", assigned by the year AND serial number of each car
(if known). The full
metadata descriptor for "Relation"
is "ex.XMP.Relation". Greenstone will search
both of these fields in the single "car serial number"
search box. For example, searching for "2065"
(look for "2065" by searching for "car serial
number") will display two photos of the 1932 TT Replica that visited the Raid at the
Lime Rock race track and the simple (nul) record originally
imported in July, 2013. See section A. above and Figure 1. The
ExifTool was later used on the original photographs in the "sep13" and "oct13"
folder, in two
steps. First, all photos had complete (and new) accession
numbers added, even those not related to the Raid. Next, those
photos intended for the Greenstone archive had "Titles"
added, exactly as done previously. This new metadata was
visible, of course, in the Picasa Album for the Raid. Later all the original Raid photos had accession numbers and
"titles" added. Individual car photos were exported and resized, as
done previously, and the photos replaced those previously in the
Frazer Nash Archive. These steps were repeated to
develop and confirm a process that can be recommended for other
collections and archives. When a photo is found
or viewed on the Frazer Nash archive (search
for "2065" as above), this photo can be saved -
"Save Image As..." - and the metadata can be reviewed
in the ExifToolGUI or other programs. The file name may
have been changed, but the original metadata has been
preserved. Alternative
Greenstone search and browsing categories are
possible,
as are changes to the display format of the search and
browsing results.
Greenstone reports it has extracted 90+ metadata items from most
digital objects, so many, many search and display formats are
possible! E.
Further
Metadata Trials and Recommendations After visiting the Frazer Nash Archives in September 2014, the
command-line ExifTool was used to create Excel spreadsheets from
more than 2,000 Frazer Nash photos in 53 subdirectories of a single
"AFNPics" folder/directory to evaluate its possible
application to the digital resources in the Frazer Nash
Archives. The ExifTool was also used to create embedded
metadata for the 800+ travel photos in England. Based on this
recent experience, these recommendations should be considered as
"next steps" for any collection of digital assets: 1. Use the
ExifTool from the command line to read entire folders/subfolders of
photos. 2. Review
the resulting Excel file ("save as" from the CSV output file)
to determine which metadata categories will help organize these
collection assets. 3. The Dublin Core categories should have high
priority, especially the "DC-Identifier" category which will
prove very useful if used for a unique "accession number" for
each digital asset. Although the documentation for the ExifTool
states that new (i.e., car-specific) metadata categories can be created,
this is complex. An accession number would be the best method to
link the default embedded metadata categories (Dublin Core and similar)
to car-specific categories that can be more easily created on a
Collections Management System (CMS) and/or Greenstone. Using
accession numbers is also a museum "best practice". 4. Use the
Excel copy/paste functions to file in missing metadata. Use the
Excel "data fill" command to create accession numbers in the
DC:Identifier category. 5. Use the
ExifTool from the command line to write the Excel file (in CSV format)
back to the entire set of photo folders/subfolders. 6. At any
future time, you may use the ExifTool again from the command line to read these
"metadata-updated" photo folders/subfolders to create data-rich Excel
files for import into a collections management, content management or
digital library (e.g. Greenstone) software program. In
conclusion, why consider creating "embedded
metadata"? Most significantly, embedding metadata in digital objects
(photos, etc.) results in those objects being very well identified for many
future uses - not only for Greenstone! Databases, Digital
Asset Management (DAM) systems and Collections Management Systems
(CMS, for archives and museums) most always can use the exported
Excel-file data directly or
indirectly as imports into their system
The online, prototype archive for the Frazer Nash, using the Greenstone Digital Library software, has been available since 2012. Using the same data, a Collections Management System (CMS) database/archive was created in 2014 using the PastPerfect software. Both systems used personal Frazer Nash data in the common Excel file format, divided into four Excel files based on PastPerfect's "museum standard" categories:
The Frazer Nash data used for the Greenstone and the PastPerfect data sets had on-going improvements as follows: Object/Resource Numbering Neither the Greenstone collection nor the PastPerfect archive initially used proper "accession numbers" to identify any photo, object, book or document. "A best practice" for museum and archives is to assign an "accession number" to everything in a collection! Further museum standards can be found on the Collections Trust website. The National Gallery of Art search example demonstrates one useful aspect of this technique. Standard accession number practice is a numbering system with several sections, separated by a period. The first section is the year an object enters the collection, and then following objects are serialized after that. Multiple objects entering in a group would get a third digit. For example, the first item added to a collection in January, 2016 would be "2016.1" Frazer Nash use of accession numbers for the "objects" departs from this practice slightly: the first Frazer Nash built in 1925 with S/N 1008 was assigned "1925.1008". None of these cars have actually "entered the collection", but this combination of year and chassis number is a useful approach. Postwar cars have serial numbers such as "421/100/168". The last three digits are uniquely adequate and easily remembered, so a specific car built in 1952 becomes "1952.168" Photos, documents, books use use the museum convention if the "collection entry date" is known and meaningful. More frequently, numbers have been assigned to the date(s) best identified with the object. A photograph or document from April, 1954 will become 1954.4.xxx with the "xxx" assigned as necessary. A spreadsheet is used record the file names, accession numbers and a description of the item. As discussed below, this data will be used eventually as "metadata" for each object/resource. Figure 6 below is a spreadsheet showing data for the early cars and the "dc.Resource_Identifier", which is the accession number. This spreadsheet was used to import data for both the Greenstone and PastPerfect systems.
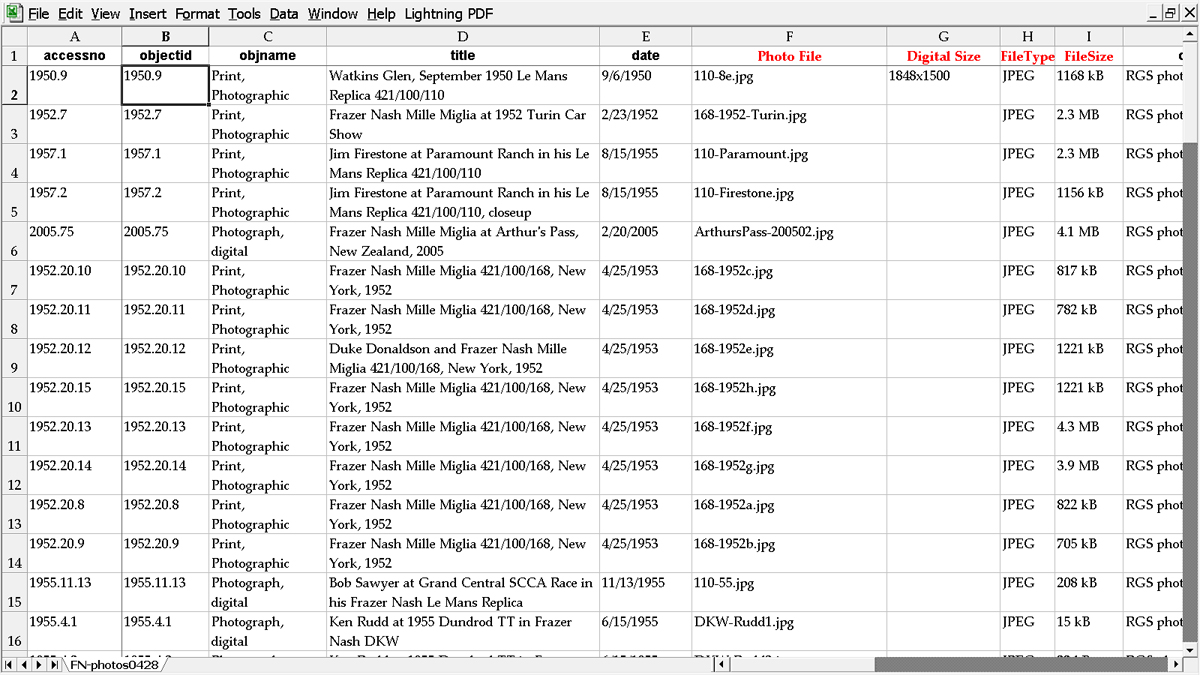
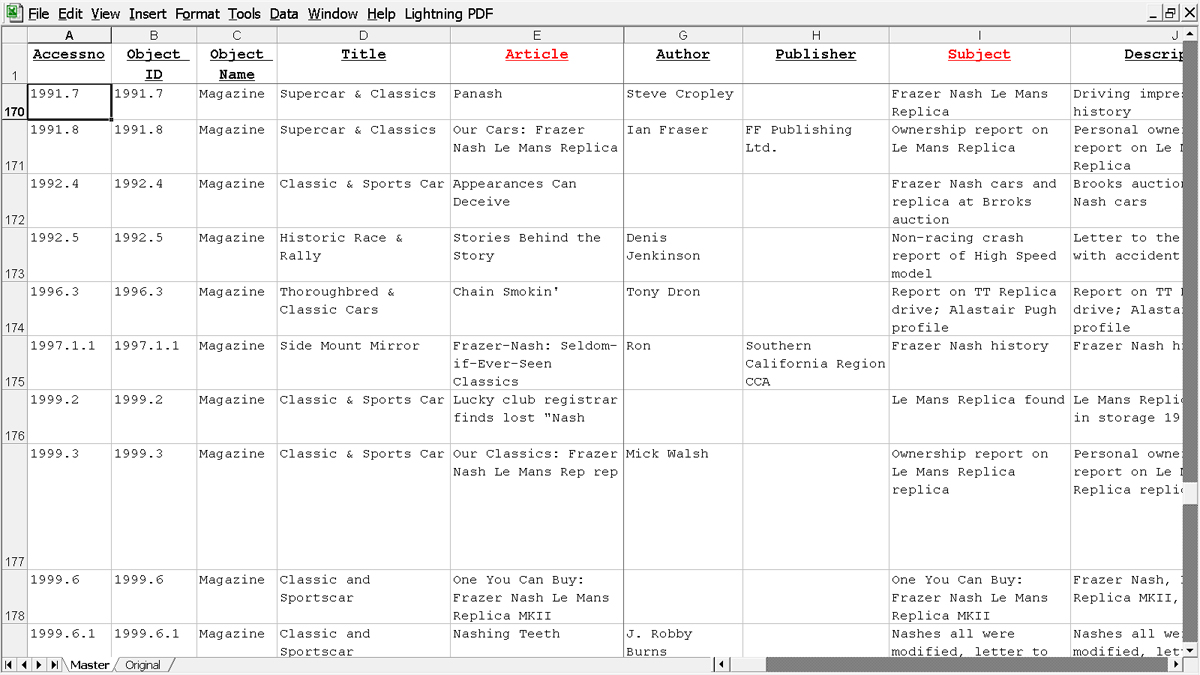
Figure 6 - Extract from a Frazer Nash spreadsheetFigure 7 below is a similar spreadsheet showing the "accessno" and data for the above-mentioned well-captioned photographs.
Figure 7 - Extract from a Frazer Nash photos spreadsheet (column headings in red are "user defined fields" added to PastPerfect)And for the library:
Figure 8 - Extract from a Frazer Nash library spreadsheetEach object in the museum/collection must have a unique accession number. This traditionally was done by recording the accession number in a log book as each object entered the collection. This archive spreadsheets are sorted and edited to eliminate duplicates. FNCC Issue 1: "Our conservator advises that they (photos) should be kept together in dedicated storage systems under controlled conditions, and museum supply companies offer lots of options for doing just this. However, storing in this way means separating the photos from the original subject files where paper items, for example, are catalogued."
FNCC Issue 2: "...photographs, above all other media, have multiple identifying parameters (date, place, people, cars, event etc.). So it is very difficult to cross reference these without reverting to something like a card index system, which is very cumbersome and doesn't sit well with the limited resources we have in the Archives."
Identifying Parameters/Standard Categories The library/museum term used for data that identifies objects, books, photos and documents is "metadata". An early standard to set metadata "categories" is the Dublin Core. From the Dublin Core User Guide:
There are many metadata classification schemes but an early and commonly recognized one is the "Dublin Core" which has 15 basic categories: see Tables 1, 2 and 3, above. The 15 categories of the Dublin Core should be considered basic; the 100+ metadata categories of PastPerfect indicate photos, objects, etc. can be described with great granularity. The Revs Digital Library is a good example of a digital photo archive with useful identification and search categories. For example, it has identified 56 Frazer Mille Miglias, including a personally-owned car at the 1952 Turin Auto show.. James Trigwell has reviewed many photos in this collection and submitted detailed captions for Frazer Nash appearances. Before Selecting a CMS FNCC Issue 3: "When we come to handling the digitised images of the photographs, the obvious choice is to consider a relational database and not a menu-driven method. There is no shortage of commercial and free software for implementing this and we would be spoilt for choice. We already have an example in our inventory as we were donated a simple database file based on Filesaver Pro containing some hundreds of photos of a GN personality. This is a general software programme rather than one dedicated to photographic images, and so probably isn't ideal. Looking further ahead, we'd like to be able to use this software in conjunction with the Archives' website currently being organised by Lou Bunting, so it should be flexible enough to import and export image files a varying formats."
Frazer Nash Bibliography An updated bibliography was published in March, 2016. Any additions or corrections are appreciated! |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||